Denna artikel ingår i serien Spring från början och kommer behandla det springstöd som finns batchjobb.
Rapporter, databearbetning eller andra bakgrundsprocesser är förhållandevis vanligt förekommande processer i många system. Dessa processer eller batchjobb kan till exempel vara enkla bash-skript som uppdaterar ett fält i en databas eller applikationer som månatligen skapar komplexa rapporter. Då den här typen av återkommande jobb ibland kräver en del resurser samtidigt som de inte alltid är beroende av att köras tillsammans med en applikation på en applikationsserver lämpar de sig många gånger väl för att köras som fristående program på separata servrar.
Spring Batch är ett ramverk från SpringSource skapat för utveckling av batchjobb. Detta ramverk erbjuder en modell, en samling verktyg samt funktionalitet tänkt att förenkla och standardisera utvecklingen av dessa typer av jobb.
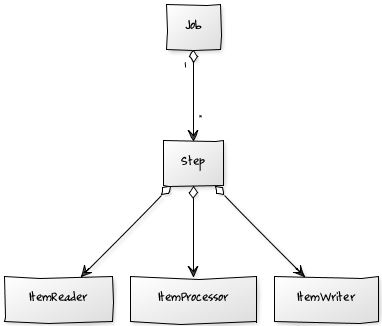
Ett batchjobb i Spring Batch är uppdelat i ett till flera steg. I varje steg läses data från en källa som sedan skrivs till ett mål. Före det att data skrivs kan denna dessutom bearbetas och transformeras i ett separat delsteg. Själva jobben konfigureras i XML men de bönor som används kan viras som vanliga Springbönor via XML eller annotationer. Exemplet nedan, med ett steg, innefattar inläsning från flatfil konfigurerat med den inbyggda läsaren av flatfiler, en enkel processor som konverterar den inlästa textsträngen och en skrivare som loggar den konverterade informationen.
<?xml version="1.0" encoding="UTF-8"?>
<beans
xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.1.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.0.xsd">
<batch:job id="readFileJob">
<batch:step id="step">
<batch:tasklet transaction-manager="transactionManager" start-limit="100">
<batch:chunk
reader="flatFileItemReader"
processor="stringLengthProcessor"
writer="simpleLogWriter"
commit-interval="5" />
</batch:tasklet>
</batch:step>
</batch:job>
<bean
id="flatFileItemReader"
scope="step"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="resource" value="${input.file.name}" />
<property name="lineMapper">
<bean
id="defaultLineMapper"
scope="step"
class="org.springframework.batch.item.file.mapping.PassThroughLineMapper"/>
</property>
</bean>
</beans>
Spring Batch kommer med inbyggt stöd för att läsa och skriva från och till flertalet olika format och källor, till exempel flatfil, XML och SQL-databaser. Det går självklart att utveckla egna readers och writers då dessa inte täcker de behov som kan tänkas finnas. Flatfilsläsaren är i exemplet konfigurerat att läsa in varje rad i en sträng som därefter skickas till en enkel processor som läser av längden på raden som sedan loggas i writern. Värt att nämna är att Spring Batch 2 stödjer generics.
@Component
public class StringLengthProcessor implements ItemProcessor<String, Integer> {
@Override
public Integer process(String s) throws Exception {
return s == null ? null : s.length();
}
}
Spring Batch 2 använder chunk-oriented processing. Varje chunk konfigureras med ett commit-interval (5 i exemplet ovan) och det är endast dessa 5 items som jobbet läser och bearbetar innan commit sker mot den konfigurerade writern.
@Component
public class SimpleLogWriter implements ItemWriter<Integer> {
...
public void write(List<? extends Integer> data) throws Exception {
for (Integer length : data) {
logger.info(length);
}
}
}
Det krävs en så kallad JobLauncher och ett konfigurerat Job för att köra ett batchjobb. Ett jobb kan till exempel startas från kommandoraden eller från en webbapplikation.
java CommandLineJobRunner readFileJob.xml readFileJob jobDateParam=2011-10-10
CommandLineJobRunner är inbyggd i Spring Batch och kräver två argument. Det första argumentet är jobPath (sökvägen till jobb-konfigurationen) och det andra är jobName (namnet på det jobb som ska köras). Utöver dessa två argument tillkommer jobbparametrar (format namn=värde). Jobbparametrarna sparas i ett jobbrepository och används för att identifiera unika jobbinstanser. Detta medför bland annat att misslyckade jobb kan återupptas och att slutförda jobb inte kommer köras igen. Vanligen är ett jobbrepository en databas men finns det inget behov att hålla reda på vilka jobb som körts och vilka som är slutförda, eller om det finns speciella prestandakrav, går det att konfigurera ett repository som hålls i minnet istället.
Utförlig dokumentation och instruktioner finns här: Spring Batch.