Bakgrund
Denna artikel beskriver den populära open source-komponenten Hibernate. Hibernate är ett s.k. Object Relational Mapping (ORM) verktyg som används för att möjliggöra persistens. Hibernate är ett av de mest aktiva och populära javaprojekten på Sourceforge och kommer garanterat dyka upp mer och mer i javabaserad systemutveckling framöver. En nyhet är att JBoss och Hibernate inlett ett samarbete där Hibernate kommer levereras med JBoss 4. Vi kommer i denna artikel introducera applikationen Petfinder för att konkretisera våra exempel. Innan vi kavlar upp ärmarna och dyker ner i Hibernate kikar vi på vad persistens är för något och vilka alternativ som finns att välja mellan.
Persistens
På ren svenska är persistens den mekanism som gör att en applikations information ”överlever” en systemomstart. Det är helt enkelt fråga om att på ett eller annat sätt lagra informationen till ett medium som i normalfallet är en hårddisk. Resvägen för informationen från instansierat objekt till lagringsmediet och åt andra hållet är olika beroende på persistensteknik. Det finns idag flera olika alternativa lösningar som passar olika situationer och framför allt olika systemkrav. Exempel på vanliga persistenstekniker inom javavärlden är:
- Enterprise Java Beans (EJB) med sina s.k. Entity beans CMP/BMP.
- JDO – Java Data Objects
- JDBC – Java Database Connectivity
- Egen lösning.
Val av persistensteknik är ett intressant och ett väldebatterat ämne som denna artikel inte tar höjd för. Ett vanligt scenario idag är att många javabaserade system stora som små bygger sin persistens kring EJB/CMP för man tror att enda vägen till god prestanda är att använda EJB. Tyvärr blir sedan följden i många fall att systemet blir onödigt komplext och att man i värsta fall misslyckas med att leverera. Vi har ambitionen att återkomma med en mer detaljerad artikel kring val av persistensmekanism. Med detta sagt börjar vi snegla på Hibernate och låt oss först förklara vad ORM är för något.
ORM – Object Relation Mapping
Hibernate är ett så kallat ORM verktyg och vad är då ORM? Object Relation Mapping är precis vad det låter som: ett verktyg som tar ett objekt och formar om det (mappar) till ett format som går att lagra i en relationsdatabas. Självklart hanterar ORM bakvägen, d.v.s. att forma om information från en relationsdatabas och skapa objekt som motsvarar informationen i databasen. Man skulle också kunna säga att applikationen pratar med Hibernate som i sin tur pratar SQL med databasen. Hibernate använder XML filer för att deklarera hur applikationens objekt hittar sin plats i databasen på rätt sätt.
Petfinder
För att få ett konkret exempel att jobba med introducerar vi härmed Petfinder applikationen. Petfinder är en applikation som hanterar husdjur som kommit bort. Här kan hussar och mattar registrera sig och sitt djur med bild och beskrivning. Sedan kan man skapa en PetIssue som i princip är en anmälan om eländet. Denna Issue hanteras sedan med olika status som sig bör. Det ska dessutom gå att registrera upphittade vilsna djur som saknar ägare för att möjliggöra att ägaren hittar sitt djur. Vi börjar med den s.k. konceptuella modellen (ibland kallad domänmodell) som visar på de olika infomationstyper som systemet måste kunna hantera. Dessutom åskådliggörs relationen mellan de olika typerna, t.ex. att en användare har mellan 0 och n husdjur. Nu är tanken inte att vi hakar upp oss på huruvida denna modell är genialiskt gjord eller inte utan återigen, vårat fokus är att visa hur Hibernate fungerar! Vi har valt att namnsätta allt kring själva systemutvecklingen på engelska av flera skäl. Först och främst är det en vanesak att döpa sina klasser och variabler på engelska, sedan för att följa den sk JavaBeans specifikationen måste vi ändå namnge ”accessors” för getXxxxx, setXxxxx alt. i boolean fallet isYyyyy. Metoder som heter t ex isBortsprungen() känns lite pinsamma :-)
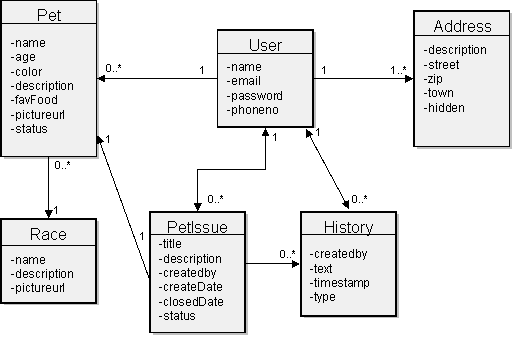
Med den konceptuella modellen på plan kan vi knalla vidare i systemdesignen och utan krussiduller presenteras här ett klassdiagram över Petfinders modell i tre olika klassdiagram.
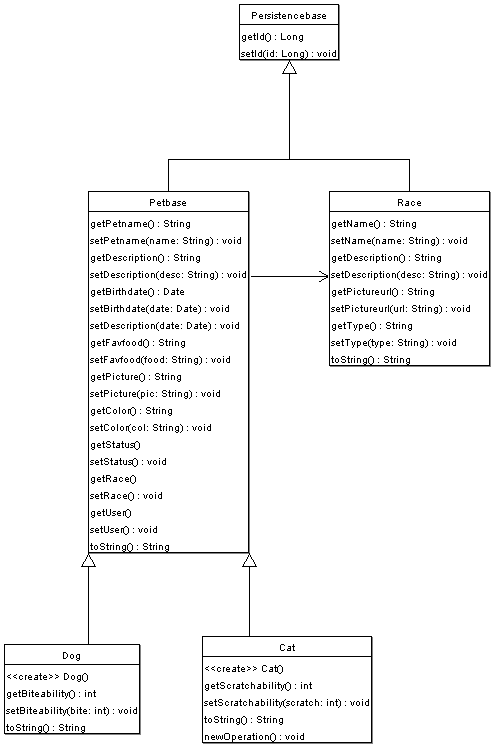
UML – Djuren
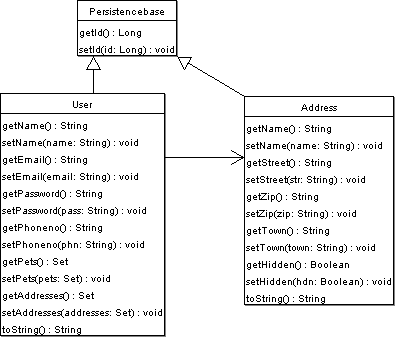
UML – Användardelen
UML – Ärendedelen
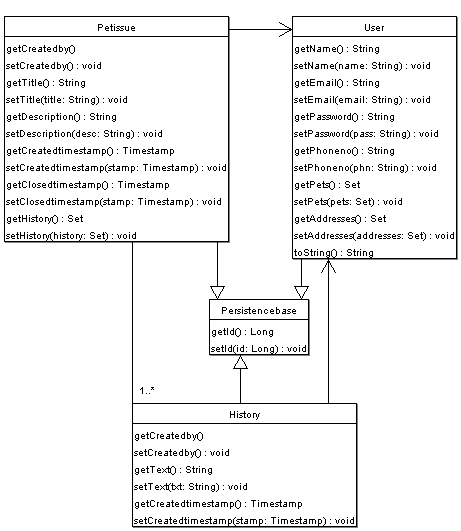
Dessa UML modeller avser hela systemets informationmodell men vi kommer i våra exempel nedan koncentrera oss på den första delen, dvs den som avser djuren. Kort om dessa klasser:
- Persistencebase – Gemensam basklass för samtliga persistenta objekt, dvs de objekt som vi vill att Hibernate ska hantera åt oss.
- Petbase – Gemensam basklass för hund och katt.
- Cat & Dog – Konkreta klasser för resp. husdjur. Avgränsas här i artikel till enbart hund och katt. Självklart ska ett komplett system hantera allt ifrån fågel till kräldjur med länkinformation till motgift och liknande!
- Race – Rasinformation. Applicerbar för både katt och hund.
Databasen
Vi kommer senare att visa hur Hibernate kan hjälpa oss att automatgenerera databasscript för din favorit RDBMS men för att inte gå vilse i avancerade verktyg inleder vi med att vi själva skapar databasen för våran applikation. Själva mappningsarbetet blir lättare att få koll på med en databas på plats. Först har vi databasmodellen.
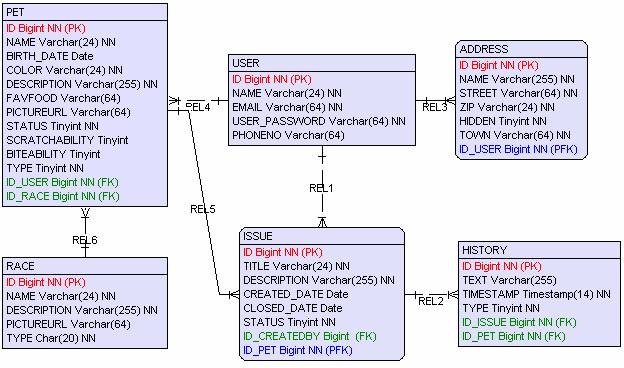
Ett laddningsscript skulle kunna se ut så här för en MySQL 4.x databas.
Create table PET (
ID Bigint NOT NULL ,
NAME Varchar(24) NOT NULL ,
BIRTH_DATE Date ,
COLOR Varchar(24) NOT NULL ,
DESCRIPTION Varchar(255) NOT NULL ,
FAVFOOD Varchar(64) ,
PICTUREURL Varchar(64) ,
STATUS Tinyint NOT NULL ,
SCRATCHABILITY Tinyint ,
BITEABILITY Tinyint ,
TYPE Tinyint NOT NULL ,
ID_USER Bigint NOT NULL ,
ID_RACE Bigint NOT NULL ,
Primary Key (ID)) TYPE = MyISAM;
Create table RACE (
ID Bigint NOT NULL ,
NAME Varchar(24) NOT NULL ,
DESCRIPTION Varchar(255) NOT NULL ,
PICTUREURL Varchar(64) ,
TYPE Char(20) NOT NULL ,
Primary Key (ID)) TYPE = MyISAM;
Create table USER (
ID Bigint NOT NULL ,
NAME Varchar(24) NOT NULL ,
EMAIL Varchar(64) NOT NULL ,
USER_PASSWORD Varchar(64) NOT NULL ,
PHONENO Varchar(64) ,
Primary Key (ID)) TYPE = MyISAM;
Create table ADDRESS (
ID Bigint NOT NULL ,
NAME Varchar(255) NOT NULL ,
STREET Varchar(64) NOT NULL ,
ZIP Varchar(24) NOT NULL ,
HIDDEN Tinyint NOT NULL ,
TOWN Varchar(64) NOT NULL ,
ID_USER Bigint NOT NULL ,
Primary Key (ID,ID_USER)) TYPE = MyISAM;
Create table ISSUE (
ID Bigint NOT NULL ,
TITLE Varchar(24) NOT NULL ,
DESCRIPTION Varchar(255) NOT NULL ,
CREATED_DATE Date ,
CLOSED_DATE Date ,
STATUS Tinyint NOT NULL ,
ID_CREATEDBY Bigint ,
ID_PET Bigint NOT NULL ,
Primary Key (ID,ID_PET)) TYPE = MyISAM;
Create table HISTORY (
ID Bigint NOT NULL ,
TEXT Varchar(255) ,
TIMESTAMP Timestamp(20) NOT NULL ,
TYPE Tinyint NOT NULL ,
ID_ISSUE Bigint NOT NULL ,
ID_PET Bigint NOT NULL ,
Primary Key (ID)) TYPE = MyISAM;
Alter table ISSUE add Index IX_REL5 (ID_PET);
Alter table ISSUE add Foreign Key (ID_PET) references PET (ID);
Alter table PET add Index IX_REL6 (ID_RACE);
Alter table PET add Foreign Key (ID_RACE) references RACE (ID);
Alter table ADDRESS add Index IX_REL3 (ID_USER);
Alter table ADDRESS add Foreign Key (ID_USER) references USER (ID);
Alter table PET add Index IX_REL4 (ID_USER);
Alter table PET add Foreign Key (ID_USER) references USER (ID);
Alter table ISSUE add Index IX_REL1 (ID_CREATEDBY);
Alter table ISSUE add Foreign Key (ID_CREATEDBY) references USER (ID);
Alter table HISTORY add Index IX_REL2 (ID_ISSUE,ID_PET);
Alter table HISTORY add Foreign Key (ID_ISSUE,ID_PET) references ISSUE (ID,ID_PET);
Hibernate – Översikt

Hibernate kan ses som ett tunt lager mellan din applikation och JDBC som i sin tur har till uppgift att prata med databasen. Din applikation använder det Hibernate-specifika Session-objektet för att sköta persistensrelaterade operationer som t.ex. att hämta upp information, lagra uppdateringar, lägga till eller ta bort information. Det trevliga med denna modell är att man kan arbeta på ett objektorienterat sätt med vad man ofta kallar POJOs (Plain Old Java Objects). Med objektorienterat sätt menar jag att det går att få arv och t.ex. Javas Collections-ramverk att fungera ihop med Hibernates persistensmekanism. Vi kikar mer konkret på detta i exemplen senare. Nu över till konfigurationsbiten.
Hur vet Hibernate hur mina objekt ska hanteras?
När applikationen startas läser Hibernate sin inställningsfil hibernate.properties som innehåller inställningar för hur Hibernate ska hitta databasen, dvs JDBC-URL mm Innan applikationen kan börja använda Hibernate måste en så kallad SessionFactory skapas. Denna SessionFactory får vid skapandeögonblicket instruktioner om vilka klasser som ska hanteras av Hibernate kapslat i ett Configuration objekt. Denna SessionFactory skapas en gång och väl skapad kan den användas för att skapa Session objekten som applikationen sedan använder för att utföra själva persistensmagin t.ex. för att hämta en hund med id 12.
Session sess = myFactory.openSession();
Dog fido = (Dog)sess.load(Dog.class,new Long(12));
Det kan vara värt att beskriva de tre klasserna Configuration, SessionFactory och Session lite mer ingående för att få en bild av deras uppgift.
Configuration
Configuration kapslar Hibernates konfiguration bestående av de xmlfiler som mappar klasser till relationsdatabasen. När väl Configuration-objektet är skapat kan man addera till klasser som ska hanteras. T.ex.
Configuration myConfig = new Configuration();
myConfig.addClass(se.bluefish.petfinder.model.User.class);
myConfig.addClass(se.bluefish.petfinder.model.Address.class);
osv....
Genom att lägga till klasser till Configuration-objektet kommer Hibernate läsa in en mappningsfil för varje adderad class med ändelse .hbm.xml. För t.ex. User-klassen läses filen se/bluefish/petfinder/model/User.hbm.xml från classpath. Det finns även andra sätt att ange konfigurationen m.h.a addFile, men det är bättre att hålla sina resurser i classpath. För webutvecklaren gäller då alltså att paketera sina .hbm.xml filer i en jar fil under WEB-INF/lib eller som ”exploided” dvs som separerade filer under WEB-INF/classes/se/bluefish/petfinder/User.hbm.xml
Lämpligtvis låter man Ant sköta detta förstås!
SessionFactory
SessionFactory är en ”fabrik för sessioner”. Dess uppgift är att tillhandahålla Session-objekt till den som vill komma åt eller uppdatera persistenta objekt. Denna SessionFactory skapas normalt vid uppstart av applikationen och knyts till något objekt som lever till dess att applikationen stängs ner. För en webapplikation knyts den lämpligtvis till ServletContext och för en standalone-applikation får applikationen själv se till att knyta upp detta objekt på något internt kontextobjekt. För att skapa en SessionFactory behöver man ett Configuration-objekt. T.ex.
SessionFactory sessFact = myConfig.buildSessionFactory();
myAppCtx.setHibernateSessionFactory(sessFact);
osv....
Session
Session-objektet är kanske det viktigaste objektet och samtidigt det objekt som kan vara lurigast att förstå. Det kan vara bra att läsa igenom delarna som förklarar detaljer kring flush och transaktioner m.m. i Hibernates manual. Iallafall har Session-objektet som uppgift att kapsla JDBC-koppling och alla persistensoperationer ska gå via detta objekt. En ofta förekommande missuppfattning är att varje gång man gör openSession() för att hämta ett Session-objekt så öppnar man också bakom kulisserna en JDBC-koppling. Så är inte fallet, utan först när Hibernate anser att nu behövs en JDBC-koppling, så hämtas en från den definerade JDBC-poolen. Alltså ska man inte vara alltför rädd att hämta en Session. T.ex. är en smart lösning för webbapplikationer att låta ett ServletFilter hämta en Session för varje inkommande anrop och sedan på tillbakavägen stänga Sessionen. Mer om detta i Arkitektur-avsnittet.
Hur får man då tag på ett Session objekt?
Session sess = sessFact.openSession();
sess.load ....
Här är ett mer komplett exempel (inkl. transaktionshantering) som det beskrivs och rekommenderas i Hibernate manualen.
Session sess = factory.openSession();
Transaction tx = null;
try {
tx = sess.beginTransaction();
// Gör det du ska ...
tx.commit();
}
catch (Exception e) {
if (tx!=null) tx.rollback();
throw e;
}
finally {
sess.close();
}
Exempel: Mappning
Vi ska här kika på hur vi mappar klasserna Dog och Cat till vår databas. Vi kommer primärt att mappa djurens basklass Petbase. Sedan pekar vi konkret ut Dog och Cat mha Hibernates discriminator-attribut, mer om detta nedan. Det hela innebär konkret att vi skapar mappningsfilen Petbase.hbm.xml för att beskriva det hela. Vi kommer senare se hur vi kan låta kombinationen ant/XDoclet/Hibernate generera dessa mappningsfiler och hålla mappningsinformationen som javadoc-taggar istället för separerat i XML-filer som handknackas. För att inte fastna i vinkelvolten börjar vi med att göra det hela för hand. En av Hibernates stora styrkor är den flexibilitet som finns för hur man kan mappa en eller flera klasser mot en databas. Vi kommer i denna artikel att enbart se en bråkdel av alla finesser som Hibernate erbjuder. Den intresserade bör dyka ner i Hibernates dokumentation för detaljer och finlir i ämnet.
Vi tittar först på klassen Dog med dess basklasser (Petbase resp. Persistencebase) för att sedan kika på mappningsfilen.
Klassen Dog.java
package se.bluefish.petfinder.model;
public class Dog extends Petbase {
protected int m_biteability;
public Dog() {}
public int getBiteability() {
return m_biteability;
}
public void setBiteability(int bite) {
m_biteability = bite;
}
}
Klassen Petbase.java
package se.bluefish.petfinder.model;
import java.sql.Date;
/**
* Petbaseclass that encapsulates the most attributes of a Pet
* @author torben
*/
public class Petbase extends Persistencebase {
protected String m_petname;
protected String m_description;
protected Date m_birthdate;
protected String m_favfood;
protected String m_color;
protected String m_picture;
protected Race m_race;
protected Petstatus m_status;
protected User m_user;
public String getPetname() {
return m_petname;
}
public void setPetname(String name) {
m_petname = name;
}
public String getDescription() {
return m_description;
}
public void setDescription(String desc) {
m_description = desc;
}
public Date getBirthdate() {
return m_birthdate;
}
public void setBirthdate(Date date) {
m_birthdate = date;
}
public void setDescription(Date date) {
m_birthdate = date;
}
public String getFavfood() {
return m_favfood;
}
public void setFavfood(String food) {
m_favfood = food;
}
public String getPicture() {
return m_picture;
}
public void setPicture(String pic) {
m_picture = pic;
}
public String getColor() {
return m_color;
}
public void setColor(String col) {
m_color = col;
}
public Petstatus getStatus() {
return m_status;
}
public void setStatus(Petstatus state) {
m_status = state;
}
public Race getRace() {
return m_race;
}
public void setRace(Race race) {
m_race = race;
}
public User getUser() {
return m_user;
}
public void setUser(User user) {
m_user = user;
}
public String toString() {
return "Petname: "
+ m_petname
+ " desc: "
+ m_description
+ m_race
+ m_status;
}
}
Klassen Persistencebase.java
package se.bluefish.petfinder.model;
import java.io.Serializable;
public class Persistencebase implements Serializable {
protected Long m_id;
public Long getId() {
return m_id;
}
public void setId(Long id) {
m_id = id;
}
}
Mappningsfilen Petbase.hbm.xml
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC
"-//Hibernate/Hibernate Mapping DTD 2.0//EN"
"http://hibernate.sourceforge.net/hibernate-mapping-2.0.dtd">
<hibernate-mapping>
<class name="se.bluefish.petfinder.model.Petbase" table="PET"> 1
<id name="id" column="id" type="java.lang.Long">2
<generator class="hilo">
</generator>
</id>
<discriminator column="TYPE" />5
<property name="petname" column="NAME"/>3
<property name="birthdate" column="BIRTH_DATE"/>
<property name="color" column="COLOR"/>
<property name="description" column="DESCRIPTION"/>
<property name="favfood" column="FAVFOOD"/>
<property name="picture" column="PICTUREURL"/>
<many-to-one name="race" column="ID_RACE"/>4
<many-to-one name="user" column="ID_USER"/>
<subclass name="se.bluefish.petfinder.model.Dog" discriminator-value="1">6
<property name="biteability" column="BITEABILITY"/>
</subclass>
<subclass name="se.bluefish.petfinder.model.Cat" discriminator-value="2">
<property name="scratchability" column="SCRATCHABILITY"/>
</subclass>
<component name="status"> 7
<property name="statuscode" column="STATUS"/>
</component>
</class>
</hibernate-mapping>
Här följer en kort beskrivning av de ingående elementen i Petbase.hbm.xml
- Beskriver kopplingen klass – tabell.
- Definerar hur Hibernate ska hantera ”id-nummer” i tabellen. Här finns en hel hög med olika lösningar. Allt ifrån Oracle sequence, MS SQL Identity och separerade ”räknartabeller”. Återigen, kika i Hibernate-manualen för detaljer kring de olika alternativen som finns!
- Kopplingen mellan klassens property och tabellens kolumn. Här finns en massa mer detaljerad information i manualen kring ”finlirsparametrar”.
- Kopplar ihop Petbase med dess husse, matte (User) samt på samma sätt djurets ras.
- Första delen av subklasshanteringen, här pekar man ut den kolumn som sitter på typ-informationen.
- Andra delen av subklasshanteringen, där man pekar ut vilket ”discriminator-värde” som innebär vilken subklass. Dessutom anges här subklassens properties.
- Mha component kan man t.ex. kapsla ett statusvärde i sin egen typ istället för att enbart låta en status ”vara en int” direkt på Petbase-klassen. Stöd för god objektorientering helt enkelt.
En sak som genomsyrar Hibernate är att det märks att det finns ett fokus på att förenkla utvecklingsarbetet för oss utvecklare. Det märks t.ex. i mappningsfiler där man ofta klarar sig med att ange väldigt få parametrar för att saker ska fungera. Det finns ett gediget tankearbete bakom val av defaultvärden. Reflektion används frekvent bakom kulisserna för att t.ex. förstå att getBirthdate / setBirthdate använder datatypen Date, vi behöver alltså inte ange detta då Hibernate själv listar ut detta m.h.a. Javas reflection-apier.
Exempel: Hämta information
Med mappningar i form av en Petbase.hbm.xml på plats kan vi nu titta på hur vi hämtar våra persistenta objekt från databasen mha Hibernate. Det finns ett antal olika sätt att få Hibernate att hämta informationen lämpliga för olika scenarion. Vi börjar med det enklaste där vi vet id på vårt objekt för att sedan titta på mer avancerade metoder.
Hämta information utifrån ett känt id
För att hämta en hund med id 1 används load metoden på session-objektet.
Session sess = myFactory.openSession();
Dog dogOfInterest = (Dog)sess.load(Dog.class,new Long(1));
Inga konstigheter här. Värt att notera är att Hibernate sköter ”SQL-arbetet” åt oss. En viktig detalj är att Hibernate dessutom tar hänsyn till vilken RDBMS som används. Har vi definerat att vi kör MySQL så vet Hibernate hur just MySQL vill att en SQL sats ska se ut. Vi har fått ett oberoende till vilken databas som används vilket är riktigt trevligt! Ett bra tips är att slå på ”show_sql” så kan man se vilka SQL-satser som t.ex. ”load” resulterar i. I produktionsmode slår man förstås av ”show_sql” av prestandaskäl. En annan sak som är värd att notera är att Hibernate dessutom hämtar rasinformationen som lagras i en separat tabell, dvs vi behöver inte precisera detta. Dock finns sätt att få Hibernate att låta bli att ladda ”beroende objekt” i första läget för att först när applikationen accessar denna information hämta upp dessa objekt. Detta kallas för lazy-loading och rätt konfigurerat kan detta innebära stora prestandavinster. Vi kikar mer på detta under prestandasektionen.
Hämta flera objekt (kollektion)
Hibernate har ett eget frågespråk som kallas HQL. Med HQL kan man liknande SQL hämta information på olika sätt, t.ex. så kan vi hämta alla hundar med rasnamn=Dobberman genom följande kodsnutt.
Session sess = myFactory.openSession();
Query q = sess.createQuery(
"from se.bluefish.pefinder.model.Dog as dog where dog.race.name = 'Dobberman'");
List dobbermanList = q.list();
// Gör något med hundlistan...
sess.close();
Har man jobbat med SQL känner man igen sig och HQL har med tiden blivit riktigt kraftfullt och klarar idag det mesta av de sökmekanismer som finns i SQL. Kika i Hibernatemanualen för detaljer kring vad som går och inte går.
Exempel: Uppdatera information
Vi måste också kunna uppdatera informationen som vi hämtat. Hur går detta till? Jo, det är inte svårare än att anropa set-metoder på våra persistenta objekt. Hibernate håller själv reda på ifall objekten behöver lagras. Innan vi kikar på detaljerna tar vi ett exempel.
// Hämta hund nummer 1
Session sess = myFactory.openSession();
Dog dogOfInterest = (Dog)sess.load(Dog.class,new Long(1));
dogOfInterest.setPetname("Cujo");
dogOfInterest.setBiteability(5);
dogOfInterest.getStatus.setStatuscode(Petstatus.STATE_ALIVE_LOST);
sess.flush();
sess.commit();
Vi behöver alltså enbart uppdatera våra objekt och Hibernate sköter allt prat med databasen. Metoden flush tvingar Hibernate att exekvera SQL, dvs synkronisera de persistenta objektens status med databasen, dock kan även Hibernate själv göra bedömningen att nu måste synkronisering ske. Enkelt förklarat så håller Hibernate koll på ordningsföljder saker får ske i och ser till att vi inte sitter med inaktuell information. Det kan ju vara så att en annan tråd försöker accessa samma objekt som någon håller på att uppdatera och här ser Hibernate till att informationen som uppdaterades synkas innan den andra tråden kommer åt informationen. Mer detaljer kring detta ämne hittas förstås i Hibernatemanualen.
Exempel: Övrigt
Förutom att hämta och uppdatera information går det självklart att skapa nya objekt som Hibernate ser till att skapa i databasen samt att ta bort objekt med features liknande de man hittar i dagens RDBMS system som t.ex. cascade m.m.
Hibernate miljötekniskt
Vi ska här titta på vilka jarfiler vi behöver för att Hibernate ska fungera, dessutom ska vi se mer detaljerat vilka konfigurationsfiler Hibernate förväntar sig och var vi placerar dessa.
Bra att ha på sin CLASSPATH
De jarfiler vi behöver i vår CLASSPATH för att använda Hibernate är följande och finns med i Hibernate distributionen under /lib katalogen (hibernate2.jar ligger på rooten). Ev. har jag missat någon jar-fil, men allt som behövs ska ingå i distributionen och beroende på hur man konfigurerar Hibernate förväntas olika jar-filer för att köra.
- hibernate2.jar
- dom4j.jar
- cglib-asm.jar
- c3p0.jar Ifall c3p0 connectionpool används.
- commons-logging.jar
- odmg.jar
- xerces.jar (Alt. annan JAXP parser)
- min_aktuella_jdbc_drivrutin.jar I vårt fall mysql-connector-java-3.0.7-stable-bin.jar
Förutom dessa jarfiler måste vi placera våra mappingfiler (t.ex. Petbase.hbm.xml) i CLASSPATH. Lämpligtvis använder man Ant och paketerar dessa i en jarfil mha Ant. Under utveckling innebär det förstås också att xyzzy.hbm.xml filerna måste nås via CLASSPATH. En annan självklarhet är att våra applikationsklasser ska vara med i CLASSPATH!
Konfigurationsfiler
hibernate.properties
Vi har tidigare nämnt hibernate.properties vilken innehåller databas-URL m.m. Denna fil placeras vid körning i CLASSPATH (rooten). Här är ett enkelt exempel på hur den kan se ut för Petfinder där vi använder MySQL 4.x som databas.
# Petfinder - Hibernate properties
hibernate.connection.driver_class=com.mysql.jdbc.Driver
hibernate.connection.url=jdbc:mysql://127.0.0.1:3306/petfinder
hibernate.connection.username=root
hibernate.connection.password=hemlishemlis# För applikationer med hög last måste nedan värden "tweakas"
hibernate.c3p0.max_size=10
hibernate.c3p0.min_size=0
hibernate.c3p0.max_statements=10
# Här anger vi att Hibernate ska prata SQL på "MySQL språk"
hibernate.dialect=net.sf.hibernate.dialect.MySQLDialect
# Vi har här valt att slå av SQL loggningen
hibernate.show_sql=false
Bygger man en webapplikation placeras lämpligtvis hibernate.properties under WEB-INF/classes
commons-logging.properties
Vi har inte nämnt hur Hibernate själv hanterar sin loggning men precis som fler och fler gör så används Jakarta commons-logging som loggningsramverk. En vanlig lösning är att delegera loggningen från commons-logging till ett annat loggningsramverk som heter log4j, också en jakarta produkt. Det hela innebär att vi behöver först en commons-logging.properties på vår CLASSPATH. Här ett exempel:
# commons-logging.properties som enbart delegerar precis allt till log4j
org.apache.commons.logging.Log=org.apache.commons.logging.impl.Log4JCategoryLog
Givetvis måste vi också se hur log4j.properties kan se ut.
# En enkel "console appender"
log4j.rootLogger=INFO, console
log4j.logger.se.bluefish.petfinder=DEBUG
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%5p [%t] (%F:%L) - %m%n
Log4j är en riktigt flexibel logglösning som vi inte dyker ner i här men kort kan sägas att ovan nämnda konfigurering styr all loggning till consolen, dvs skärmen. Vi sätter övergripande loggnivå till INFO och för petfinder skruvar vi upp detaljer till DEBUG-nivå. Givetvis är denna log4j-konfiguration inte produktionslämplig, utan är enbart för utveckling. I ett produktionsscenario loggar man förstås till fil eller i UNIX-miljö till syslog:en.
Hibernate och Arkitektur
Vi har nu börjat få en bild över hur Hibernate fungerar och hur vi konfigurerar det hela. Vi är då framme vid en stor fråga och det är hur väljer man lämplig arkitektur för sin Hibernate-applikation. Vi kommer att illustrera tre konkreta fall och peka på när det är relevant att använda just detta fall och vilka svårigheterna blir för att ”ro det hela i land”. Självklart kan man hitta ”25” ytterligare scenarion som säkert kan ha sin relevanta plats men dessa tre borde ändå vara de alternativ som hanterar de vanligaste fallen.
Alternativ 1: Enkel traditionell client/server-lösning
Idag bygger man nästan allt som webbapplikationer vilket rätt så ofta blir rätt så absurt. Argumenten för att bygga webbapplikationer är att deployment är ett problem och givetvis finns relevans bakom argumentet. Samtidigt så finns idag väl etablerade tekniker för att distribuera ”riktiga applikationer”, t.ex. Java Web Start i javafallet samt andra lösningar på operativsystemsnivå. Dessa lösningar likställer tunga klienter med webapplikationer. Vi inleder här med att kika på hur en enkel client/serverlösning med en tung Javaklient skulle kunna se ut.
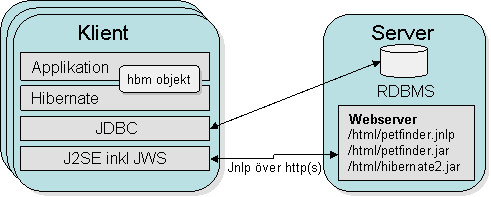
Ok, visst kan man fundera på att det hade sett snyggare ut med en EJB-container på serversidan, men det finns en prislapp som drar iväg en del när EJB dyker upp. Lösningen är förstås relevant för mindre lösningar där en klienttyp räcker.
Alternativ 2: Webapplikation utan EJB kontainer
På samma sätt som att allt idag byggs som webapplikationer finns en missuppfattning om att enda vägen till prestanda innebär att man måste använda EJB. Detta är helt fel. Vägen till hög prestanda handlar om cachning, cachning och åter cachning. Valet EJB eller inte är en fråga om behovet av ”mellan-komponenter-transaktionshantering”, komponentåteranvändning och failover hantering. Handen på hjärtat. När återanvände du en EJB mellan två projekt senast? Självklart finns ett stort behov av EJB för vissa projekt men vi ska här nedan kika på hur arkitekturen för en webapplikation utan EJB kontainer kan se ut. Exemplet nedan består av en webapplikation som använder jakarta Struts som webramverk.
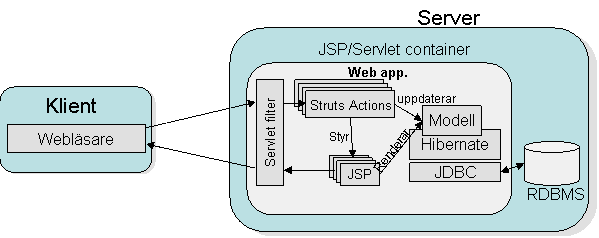
Denna lösning passar Hibernate hur bra som helst. Jag nämnde tidigt att en smidig lösning är att låta ett servletfilter tillhandahålla en Session som sedan stängs av av filtret på ”tillbakavägen” och det fina med kråksången är att det passar ett requestflöde väldigt bra. Nedan ett exempel på vad som skulle kunna ske.
- Inkommande request: Session skapas av filter.
- Logik på serversidan (Struts Action) hämtar upp information mha Hibernate. Ett objekt knyts till request-objektet för att delta i renderingen. Självklart ska en väldesignad applikation internt delegera ”affärslogiken” till ett separat delsystem på det logiska planet.
- Delegering till den jsp-sida som renderar informationen.
- jsp-sidan accessar informationen från request-objektet, ev. lazy-laddningar sker för att rendera all detaljinformation.
- Utgående request: Session stängs av filter. En liten detalj är att ifall vi stängt sessionen redan i logikexekveringen (punkt 2) så hade lazy-laddningen genererat exceptions.
Alternativ 3: Webapplikation med EJB container
Det finns förstås fall när en komplett J2EE-container är relevant. Ett bra exempel är t.ex. för applikationer som både har webbklienter (kanske mot Internet) och tunga klienter (kanske intranet-administrationsklienter) t.ex. en native Win32 / .Net-klient som pratar med en eller flera Webservices deployade i J2EE-servern. Hur kan jag i dessa fall använda Hibernate? Normalt i en EJB-applikation kapslar man sin EJB-access mha en s.k. SessionFacade, där en stateless session bean sköter kommunikationen med entity beans som i viss mån motsvarar vad Hibernate gör. Hibernate ersätter helt enkelt entity beans, dvs sessionfacade interfacet ligger kvar men istället för att prata med entity beans pratar sessionsbönan med Hibernate.
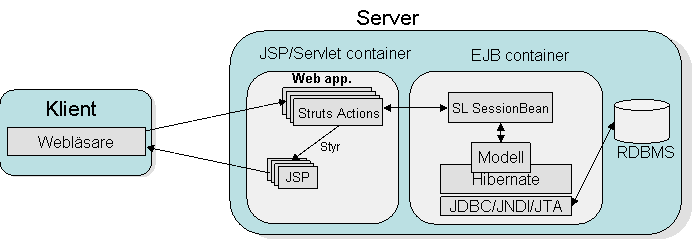
Konfigureringsmässigt talar man om för Hibernate att delta i EJB-containerns transaktionshantering vilket konkret innebär en del skruvande i hibernate.properties. Sedan behöver man göra en del container-specifik konfiguration för att Hibernate ska ”aktiveras”. Det finns idag en punkt på Hibernates utvecklingsroadmap att tillhandahålla en s.k. JCA (Java Connector Architecture) kompatibel koppling vilket på ren svenska innebär att med den på plats blir det enklare att plugga in Hibernate i J2EE-containrar. Dessutom är numera Hibernates huvudprogrammerare Gavin King anställd av JBoss group för att tillhandahålla första klassens JBoss-integration. I JBoss 4 lär vi se Hibernate som en redan integrerad del vilket blir riktigt trevligt. Ett litet problem med att placera Hibernate bakom EJB-komponenter är att lazy loading inte går att använda, dock är det en designfaktor som går att hantera. Vissa påstår att sessionhanteringen i lösning 2 är mindre bra för applikationer med väldigt hög last. En väldigt trevlig detalj är att Hibernate stödjer ”återinförandet” av objekt som tidigare lämnat EJB-lagret, eller mer korrekt inte längre deltar i en Hibernate-session. Ett vanligt exempel är när ett EJB lager levererar information till weblagret som sedan uppdaterar objekten för att sedan returnera objekten till EJB-lagret som sköter själva uppdateringen. Med entity beans krävs omtransformeringar enligt DTO pattern men i Hibernate fallet kan man i både web och EJB-lager arbeta med samma POJOs och grundläggande objektorienteringskoncept är applicerbara.
Hibernate och prestanda
På vilket sätt bidrar Hibernate till en bra prestanda? Det finns ett antal områden där Hibernate optimerar informationshanteringen.
Optimerad SQL-användning
När vår applikation uppdaterar information via Hibernate, samlar Hibernate på sig alla förändringar som sker och vid lämpliga tillfällen (atingen påtvingat av oss via flush eller under speciella omständigheter) exekveras SQL-satserna. Hibernate förstår dessutom ifall vi uppdaterar ett objekt med samma information som fanns där innan vilket kan låta självklart men det är faktiskt väldigt vanligt att applikationer spenderar allt för mycket tid på att uppdatera information till samma läge som innan vilket är slöseri med CPU-tid.
Cachning
Hur stödjer Hibernate cachning? Hibernate har en speciell plugin-arkitektur för cachning. Detta innebär att det går att köra med den vanliga JCS-Cache (lånad från Turbine-projektet) eller den kommersiella komponenten Coherence från Tangosol. Eftersom numera Hibernate och JBoss ”arbetar ihop”, kommer vi säkerligen se integration mellan JBoss distribuerade cache och Hibernate. JCS-Cache som är det alternativ som finns med idag (som är ”gratis”) låter oss konfigurera om vi har en s.k. read-only cache eller read-write cache med de parametrar man kan förvänta sig. Detaljer kring dess konfigurering och vad man bör tänka på hittas i Hibernate-manualen.
Lazy loading
Ett bra exempel på ”lazy loading” i Petfinder är att vi vill hämta alla PetIssue-objekt för de fall som ”är olösta”. Vi har dessutom mappat så att för varje PetIssue har vi ett eller flera History-objekt. Ifall Hibernate skulle hämta alla PetIssue med alla tillhörande History-objekt skulle det bli rätt tung databastrafik. Lösningen är att markera mappningen med lazy=true vilket innebär att Hibernate låter bli att hämta History-objekt innan dom verkligen behövs. Ett litet problem som kan uppkomma är dock att man stänger sessionen innan man accessar dessa ”lazy- objekt” och vips har man fått ett exception på halsen. Återigen, med arkiteturskiss två ovan hamnar man inte i detta klister.
Hibernate i praktiken
Det finns ett antal väldigt användbara verktyg som följer med Hibernate. Men innan vi nämner dessa verktyg ska vi kika på vad Ant och framförallt XDoclet kan hjälpa oss med. Vi kikar övergripande på dessa väldigt användbara verktyg som givetvis finns dokumenterade på hibernate.org
Ant/XDoclet
XML i all ära men när projektet sväller och vi har 20, kanske 50, persistenta klasser som ska mappas kan man bli lite matt. En lösning är att låta XDoclet automatgenerera mappningsfiler åt oss. XDoclet är ett verktyg som låter oss utöka Javas javadoc-sektioner med diverse meta-data. t.ex. finns det enkla verktyg som låter oss lägga in @todo taggar som XDoclet sedan kan hitta och generera en snygg navigerbar todo-lista för hela projektet. Även i EJB-världen förekommer automatgenerering av EJB-deploymentdescriptorer via XDoclet. Man skulle kunna beskriva XDoclet som en avancerad preprocessor. Ofta drivs själva processningen av Ant som sköter arbetet att rekursivt söka igenom källkodsträd efter java-filer. Vi går inte in på hur Ant eller XDoclet fungerar i detalj men här är ett exempel på hur ett ”Ant-target” för att generera Petfinders mappningar skulle kunna se ut.
<target name="hbm-gen" depends="init">
<hibernatedoclet
destdir="${src-gen}/hibernate"
mergedir="${samples.src.dir}"
excludedtags="@version,@author,@todo,@see"
addedtags="@xdoclet-generated at ${TODAY},
@copyright The XDoclet Team,@author XDoclet,@version ${version}"
force="false"
verbose="true">
<fileset dir="${src}">
<include name="**/*.java"/>
</fileset>
<hibernate version="2.0"/>
</hibernatedoclet>
</target>
I exemplet ovan genereras xyzzy.hbm.xml filer till ${src-gen/hibernate} katalogen. Självklart måste våra källkodsfiler utökas med Hibernate-specifikt meta-data. Här ser vi hur ett avsnitt av User-klassen skulle kunna se ut med XDoclet-Hibernate taggar.
/**
* @hibernate.class table="USER"
*/
public class User extends Persistencebase {
protected String m_name;
protected String m_email;
protected String m_password;
protected String m_phoneno;
protected Set m_addresses;
protected Set m_pets;
/**
* @hibernate.property column="NAME"
* @return
*/
public String getName() {
return m_name;
}
public void setName(String name) {
m_name = name;
}
...
class2hbm
I de fall man har en massa befintlig kod, kan detta verktyg hjälpa oss med att generera hbm.xml-mappningsfiler. Räkna dock med att manuellt justera de mappningsfiler som genererats så de passar din applikation.
hbm2java
Har du mappningsfiler men saknar javakod, kan detta verktyg skapa dessa filer åt dig.
ddl2hbm
Kan via jdbc analysera en databas och generera hbml.xml-mappningsfiler åt dig. Dock är detta verktyg markerat som deprecated och man hänvisar till Middlegen-verktyget istället. Vi nämner Middlegen kort nedan.
SchemaExport / SchemaUpdate
Ett bra alternativ till att skapa en databas på traditionellt sätt är att utnyttja SchemaExport-verktyget som kan generera en ddl-fil (”Databas-skapar-script”). Verktyget utgår från mappningsfilerna samt hibernate.properties och skapar ett korrekt script för den aktuella SQL-dialekten. Verktyget ser på sätt och vis till att projektet kan vara RDBMS-oberoende. Faktum är att verktyget till och med hanterar korrekt generering av sekvensnummer och skapar referensintegritet enligt vedertagna principer. Systerverktyget SchemaUpdate ser till att skapa vad som saknas, dvs i de fall när en databas inkrementellt utökas, kan SchemaUpdate lägga till de tabeller och kolumner som är nya vilket kan vara en nog så viktig funktion för projekt med en omfattande mängd information.
MiddleGen
MiddleGen är ett avancerat verktyg för att generera kod. MiddleGen kan utgå från en befintlig databas och generera i Hibernatefallet hbm.xml-filer (mappningsfiler). Sedan kan man komplettera med att låta hbm2java generera java-klasser och vips har man från en befintlig databas fått ett persistenslager att arbeta med. Det är förstås möjligt att tweaka en hel del i MiddleGen och som med all automatgenerering finns det saker som blir knöligt. MiddleGen kan iallafall ge en bra start för projekt med befintliga stora databaser som ”behöver ett ORM-lager”.
Slutord
Hibernate är en fantastisk produkt som blivit otroligt populär det sista halvåret, mycket beroende på snabb progress av funktionalitet samt projektets mycket omfattande dokumentation. Givetvis är en stor faktor att Hibernate är enkelt att förstå sig på och snabbt att komma igång med, samtidigt som Hibernate är väldigt kraftfullt. En annan anledning till Hibernates framgång kan också vara att EJB har blivit något för komplext och tungt att arbeta med på olika sätt, som utvecklare sitter man ofta och arbetar med deployment-problematik som man aldrig blir riktigt klok på. Sun har själv erkänt att EJB är för krångligt och nästkommande EJB-version 3.0 kommer garanterat att använda sig en hel del av J2SE 1.5s nya metadata-features vilket påminner mycket om XDoclet. Törs man då satsa på Hibernate i ”seriösa projekt”? Jag ser inga problem med att använda Hibernate i professionella projekt idag då man ser hur bra hjälp man får på Hibernate-forum och tidigare mailinglistor.